
<NLP Introduction>
- NLP Tasks
- Sequence to Sequence(S2S) Learning

- N21 Problem : Topic Classification, Semantic Textual Similarity, Natural Language inference
- N2N Problem : Named Entity Recognition, Morphology Analysis
- N2M Problem : Machine Translation, Dialogue Model, Summarization, Image Captioning
<PyTorch Lightning>
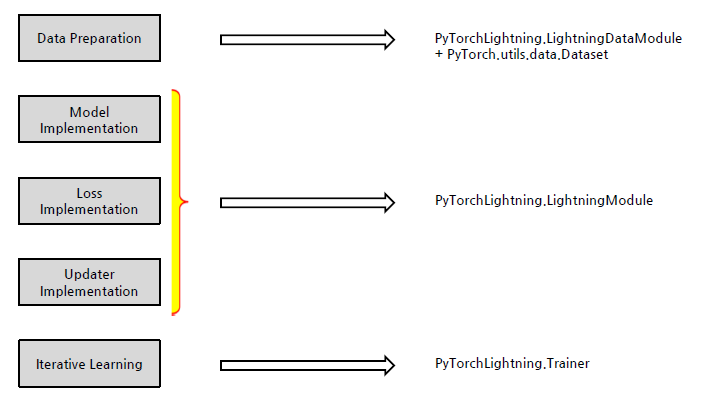
Deep Learning Process
- Data Preparation : 입출력 Data를 담는 Tensor 생성
- Model Implementation : 모델 구현
- Loss Implementation : 모델이 얼마나 틀렸는지 측정 함수 설정
- Updater Implementation : 초기 설정 parameter에서 최적 parameter로 조정하는 옵티마이저 구현
- Iterative Learning : 데이터 Feeding을 통한 모델 반복 학습 및 검증
- PyTorch Lightning은 PyTorch에 대한 High-level 인터페이스 제공, 더 높은 수준의 자동화 기능 제공

실습 - Pytorch 만 썼을 때의 문제점
- 모델을 학습하고 평가하는 반복 학습을 할때마다 dataloader를 매번 호출해야 함
- 모델과 데이터, 옵티마이저를 일일히 불러와서 코드가 중복이 되어 불편함
- 모델, 데이터, 학습 및 평가가 구조적으로 정리되지 않아 가독성이 떨어짐
!pip install pytorch-lightning- DataModule
데이터를 다운로드, 메모리 저장
-> PyTorch Dataset으로 변환, 데이터 전처리 (특히, transforms)
-> dataloader 형태로 학습/평가 분할
위 과정을 처리해주고 재사용 가능한 클래스
- configure_optimizers, training_step, validation_step, validation_epoch_end, test_step, test_epoch_end
- PyTorch Lightning 구조는 기존의 PyTorch 학습을 간단한 한줄에 묶을 수 있음
- 중복되는 Deep Learning Block을 Module들로 묶어서 모듈의 가독성과 재활용성을 높일 수 있음
<Pandas with NLP>
Pandas를 활용하여 NLP 데이터 불러오기
다양한 조건을 통해 데이터 선택/출력
NLP 데이터에 대한 분석과 시각화
Pandas로 PyTorch Dataset 구현하고 분할
<Tokenization>
- Text를 숫자로 변환하려는 시도
The Bag of Words Representation : 단어가 나타난 횟수를 세어 text를 숫자로 변환
TF-IDF(Term Frequency Inverse Document Frequency) : 단어의 빈도와 역 문서 빈도를 사용하여 DTM내의 각 단어들마다 중요한 정도를 가중치 변환
Word2Vec : 단어 벡터 간 유의미한 유사도를 반영할 수 있도록 단어의 의미를 수치화
1. text를 어떤 단위(token)로 나눌 것인가? -> Tokenization
2. token을 어떤 숫자로 바꿀 것인가? -> Embedding
https://www.dbpia.co.kr/journal/articleDetail?nodeId=NODE07434412&language=ko_KR&hasTopBanner=false
심층신경망에서의 효과적인 문장추상화를 위한 한국어 단위 연구 | DBpia
정상근 | 정보과학회논문지 | 2018.05
www.dbpia.co.kr
- Character-based Tokenization
- Word-based Tokenization
- Subword-based Tokenization
문장 혹은 단어를 통계적으로 의미있는 단위로 묶거나 분할해서 처리
- Byte Pair Encoding(BPE) - 어휘를 묶어 나가는 알고리즘


-Tools : KoNLPy(한국어), Sentencepiece, Huggingface-Tokenizer
<Transformer>
- 기존 NN의 문제점 : 기존의 신경망은 Sequence data에 대해서는 처리하기 어려움
- RNN의 문제점
1) 순차적 모델링 방식이기 때문에, Data2 를 살펴볼 때, Data1 및 Data3 가 동시에 고려될 수 없음
2) 지역 정보만 활용하기 때문에, Data3 를 모델링할 때 원거리에 있는 정보가 원활하게 활용되기 힘듦
- Attention Mechanism
- Transformer

<HuggingFace>
- Pre-training
- Fine-tuning : Pre-training된 모델을 연구 및 상용화에 맞게 특정 문제(dataset)에 대해 추가 학습
<N21>
- 접근 방법
Supervised Learning
Classification(Class 개수가 정해져 있다 가정)
- 신경망 디자인
N개 Class 정의 -> Network 구성 -> Input -> 계산 -> Class 별 Scoring


Example : Spam Classifier, News Classfication
Loss Function
Output이 숫자인 경우 - Regression - Mean Squared Error(MSE)
Output이 Category인 경우 - Classification Loass - Cross Entropy(CE)
- tokenizing, Transformer, Huggingface를 N21 문제를 통해 학습에 적용
- input : 기사 제목 ( = N tokens )
- output : 기사의 주제 ( = 1 single class )
<N2N>

- 입력 : 입력 시 데이터는 task에 알맞게 다양한 형태로 sequential하게 표현
출력 : 입력과 토큰 개수를 동일하게 정해야 함
- IO : I(label 있음), O(label 없음)
BIO : B(label 첫 글자), I(label 있음), O(label 없음)
BIOES : B(label 첫글자), I(label 있음), E(label 끝 글자), S(label 1 글자), O(label 없음)


실습
1) 주어진 데이터셋으로 음절 단위 Data Loader 구성
2) 주어진 데이터셋에 대해 Pytorch-lightning을 활용한 Transformer 모델 학습
3) 학습된 모델의 결과에 대해 Conlleval-2000의 다양한 평가 지표를 통해 평가
<N2M>
Transformers
- Encoder Only 모델
손상된 문장을 복원하거나, 문장 간의 관계를 유추하여 학습함
- Decoder Only 모델
Auto-regression
생성한 단어를 다시 입력으로 사용하여 모든 단어를 순서대로 예측함
- Encoder-Decoder
Bart, T5


실습
1) Pre-trained 모델의 토크나이저를 활용하여 데이터 전처리
2) 전처리한 데이터를 활용하여 Pre-trained 모델 Fine-tuning
3) WandB를 활용하여 학습 과정 로깅 및 로깅 결과 확인
다양한 형태의 날짜 데이터를 입력받아 YYYY-MM-DD 형태로 생성
1) N2M 실습코드 및 모델 활용
2) FastAPI를 활용한 백앤드 API 서버 구현
3) Streamlit을 활용한 데모용 웹페이지 구현
'부스트캠프 AI Tech' 카테고리의 다른 글
| Self-supervised Pre-training Models (0) | 2022.10.23 |
|---|---|
| Beam Search and BLEU score (0) | 2022.10.23 |
| Seq2Seq (0) | 2022.10.23 |
| RNN, LSTM, GRU (0) | 2022.10.12 |
| Word Embedding: Word2Vec, GloVe (0) | 2022.10.11 |




댓글