
Transformer는 nlp에서 많이 활용된다는데, 강의를 돌려봐도 잘 와닿지 않고 어려웠던 개념이다.
다음주 멘토링과 강의에서 더 자세히 배울 것 같으니 짚고 넘어가고자 글을 작성한다!
https://arxiv.org/abs/1706.03762
Attention Is All You Need
The dominant sequence transduction models are based on complex recurrent or convolutional neural networks in an encoder-decoder configuration. The best performing models also connect the encoder and decoder through an attention mechanism. We propose a new
arxiv.org
http://jalammar.github.io/illustrated-transformer/
The Illustrated Transformer
Discussions: Hacker News (65 points, 4 comments), Reddit r/MachineLearning (29 points, 3 comments) Translations: Arabic, Chinese (Simplified) 1, Chinese (Simplified) 2, French 1, French 2, Japanese, Korean, Russian, Spanish, Vietnamese Watch: MIT’s Deep
jalammar.github.io
<강의 리뷰>
Sequential한 상황에서 중간에 단어가 빠지거나, 순서가 뒤바뀌는 등의 문제가 일어나면 모델링하기 어려움
이러한 문제를 해결하는 self attention 구조의 transformer
Transformer is the first sequence transduction model based entirely on attention.
1. 입력 시퀀스, 출력 시퀀스는 단어의 수가 다를 수 있음
2. 입력 시퀀스, 출력 시퀀스 각 도메인이 다를 수 있음
<이해해야 하는 것>
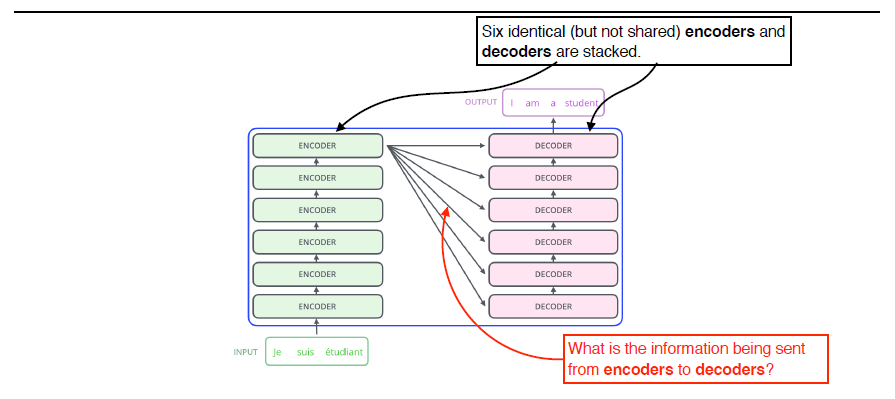
1. 트랜스포머의 인코더는 몇 개의 단어가 들어가든 재귀적으로 n번 도는 것이 아니라 한 번에 처리함. n개의 단어가 어떻게 인코더에서 한 번에 처리되는가?
2. 인코더와 디코더 사이에서 어떤 정보를 주고받는가?
3. 디코더가 어떻게 generation할 수 있는가?

n개의 출력값이 다음 레이어 인코더에 들어가는 방식으로 스택됨.
The Self-Attention in both encoder and decoder is the cornerstone of Transformer.


self-Attention에는 dependency가 있음
X1에서 Z1로 넘어갈 때, 나머지 n-1개의 X벡터를 고려함
The animal didn't cross the street because it was too tired.
이 문장에서 it은 무엇을 가리킬지를 판단할 때
인코딩하면서 it의 다른 단어와의 관계성을 학습함

각 임베딩 벡터마다 쿼리, 키, 밸류 벡터가 주어짐
쿼리 벡터와 키 벡터를 내적함으로써 얼마나 interation 일어나는지 판단
차원으로 나누고, softmax를 취하고, value를 곱하고 다 더해줌으로써 z를 구함


매트릭스 폼으로 이해하기!
Transformer는 하나의 input이 고정되어있다 하더라도, 다른 단어들에 따라 인코딩 값이 달라지게 됨
많은 것을 표현할 수 있고 flexible한 transformer
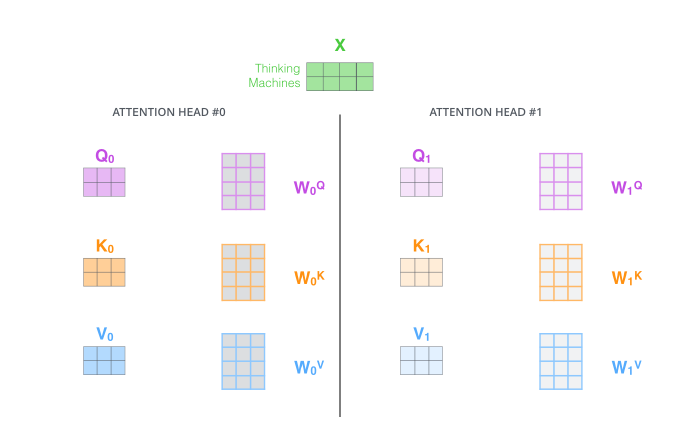
Multi-headed attention (MHA) : 하나의 임베딩 벡터에 n개의 쿼리, 키. 밸류 벡터를 만듦
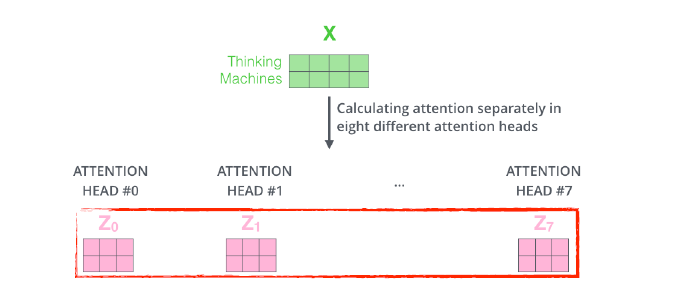
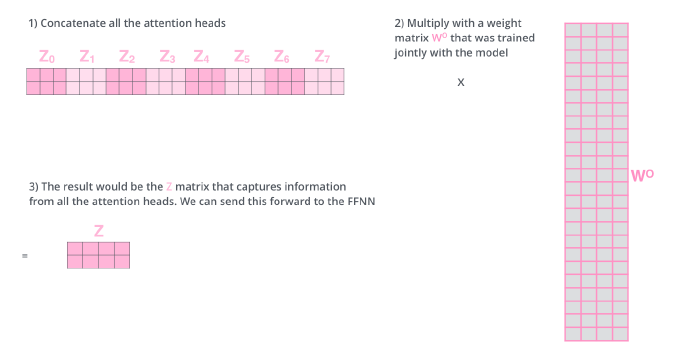
8개의 헤드가 사용되었다면, 이렇게 8개의 인코딩 된 결과가 나옴
입력과 출력의 차원을 맞춰주어야 함

실제로 구현할 때는
원래 임베딩된 벡터가 100차원이고, 10개의 헤드를 사용한다고 하면
100차원을 10개로 나눠 10차원의 입력만 갖고 쿼리,키, 밸류, 벡터를 만듦

self attention의 동작 방식은 orderly independent한데,
문장은 단어 순서가 중요하므로 주어진 입력에 Positional encoding이 필요함

트랜스포머는 디코더에 key와 value를 보냄
input 단어에서 디코더의 출력하고자 하는 단어에 대한 attention map를 만들기 위해 상위에 있는 key와 value 벡터를 전달하는 것임
디코더에 들어가는 단어들로 만들어지는 쿼리 벡터와 입력단어로 만들어진 키,밸류 벡터들을 갖고 최종값이 나옴
In the decoder, the self-attention layer is only allowed to attend to earlier positions in the output sequence which is done by masking future positions before the softmax step.
The “Encoder-Decoder Attention” layer works just like multi-headed selfattention, except it creates its Queries matrix from the layer below it, and takes the Keys and Values from the encoder stack.
<강의를 다 듣고 든 생각>
인코더에서 디코더로는 왜 key와 value가 전달되는 것인가?
인코더에서 만들어진 z벡터가 결국 어떻게 쓰이는 것인가?
전체적인 흐름에 대한 이해가 부족한 것 같음
코리안 버전을 보며 다시 한번 공부해보자
(읽는중)
새롭게 알게 된 내용들 중심으로 정리
The Illustrated Transformer – NLP in Korean – Anything about NLP in Korean
The Illustrated Transformer
저번 글에서 다뤘던 attention seq2seq 모델에 이어, attention 을 활용한 또 다른 모델인 Transformer 모델에 대해 얘기해보려 합니다. 2017 NIPS에서 Google이 소개했던 Transformer는 NLP 학계에서 정말 큰 주목을
nlpinkorean.github.io
- 핵심 : multi-head self-attention을 이용해 sequential computation 을 줄여 더 많은 부분을 병렬처리가 가능하게 만들면서 동시에 더 많은 단어들 간 dependency를 모델링
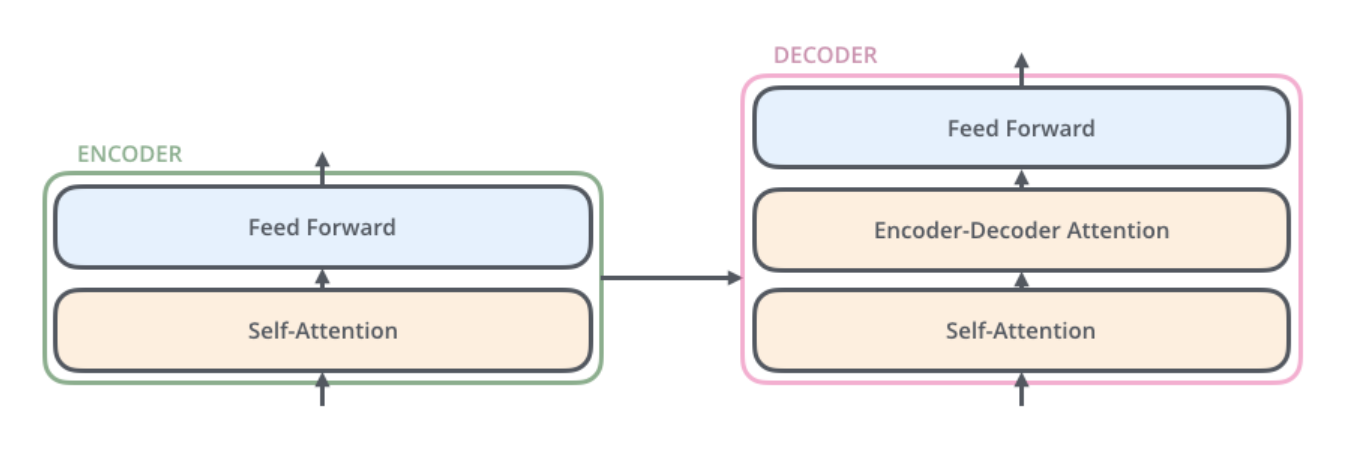
- decoder 또한 encoder에 있는 두 layer 모두를 가지고 있음. 그러나 그 두 층 사이에 encoder-decoder attention 이 포함되어 있음. 이는 decoder가 입력 문장 중에서 각 타임 스텝에서 가장 관련 있는 부분에 집중할 수 있도록 해줌
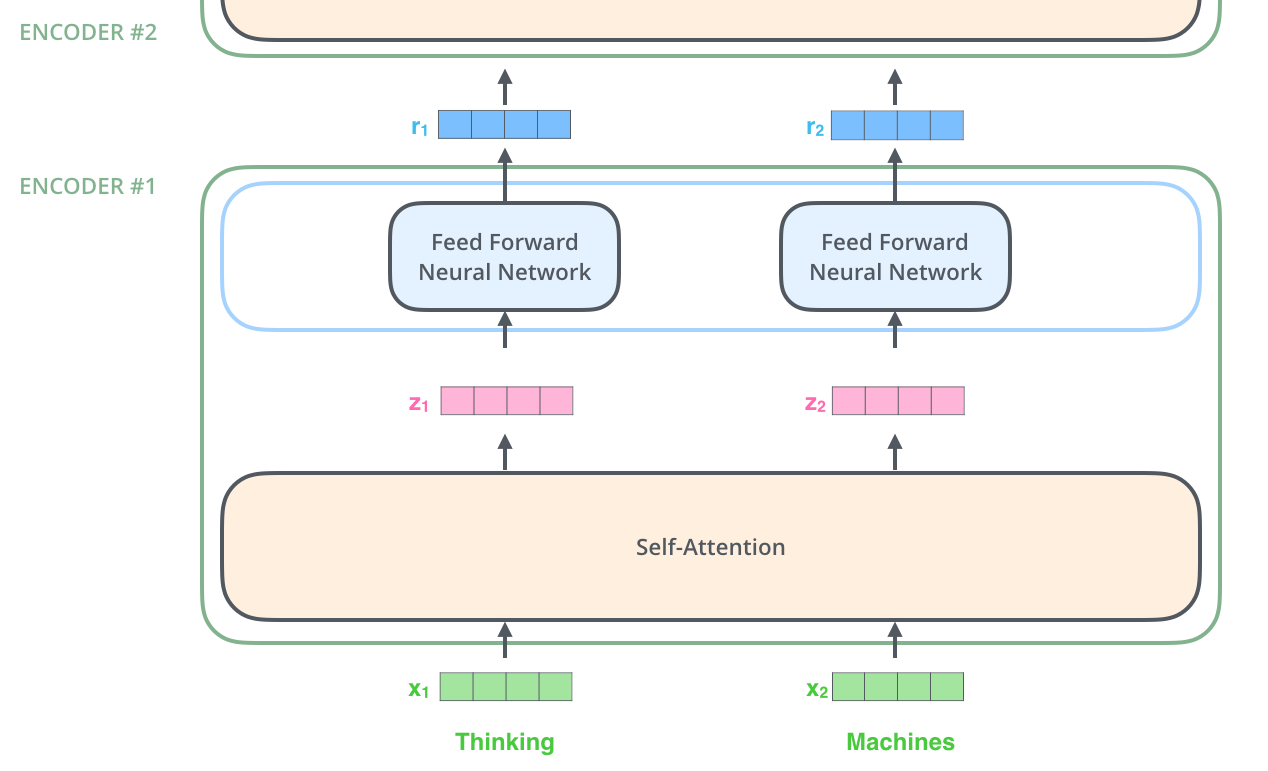
- encoder는 입력으로 벡터들의 리스트를 받음. 이 리스트를 먼저 self-attention layer에, 그다음으로 feed-forward 신경망에 통과시키고 그 결과물을 그다음 encoder에게 전달함
Q. 처음 x1을 받아 Self-Attention으로 z1이 나오고, 그리고 FFNN을 거쳐 나온 r1을 그다음 인코더에서는 x1으로 인식하는 것인가?
- multi-headed attention
1. 모델이 다른 위치에 집중하는 능력을 확장시킴. 위의 예시에서는 z1 이 모든 다른 단어들의 encoding 을 조금씩 포함했지만, 사실 이것은 실제 자기 자신에게만 높은 점수를 줘 자신만을 포함해도 됐을 것임. Q. 무슨 말이지? 이것은 “그 동물은 길을 건너지 않았다 왜냐하면 그것은 너무 피곤했기 때문이다” 과 같은 문장을 번역할 때 “그것”이 무엇을 가리키는지에 대해 알아낼 때 유용함.
2. attention layer 가 여러 개의 “representation 공간”을 가지게 해줌
- Positional Encoding
Transformer 모델에서 한가지 부족한 부분은 이 모델이 입력 문장에서 단어들의 순서에 대해서 고려하고 있지 않다는 점 so Transformer 모델은 각각의 입력 embedding에 “positional encoding”이라고 불리는 하나의 벡터를 추가함. 이 값들을 단어들의 embedding에 추가하는 것이 query/key/value 벡터들로 나중에 투영되었을 때 단어들 간의 거리를 늘릴 수 있다는 점이 있음. Q. 입력 임베딩에 Positional Encoding을 추가하면 쿼리, 키, 밸류 벡터에 어떤 형태로 위치 차이를 알 수 있는 것인가?
- 각 encoder 내의 sub-layer 가 residual connection으로 연결되어 있으며, 그 후에는 layer-normalization 과정을 거침
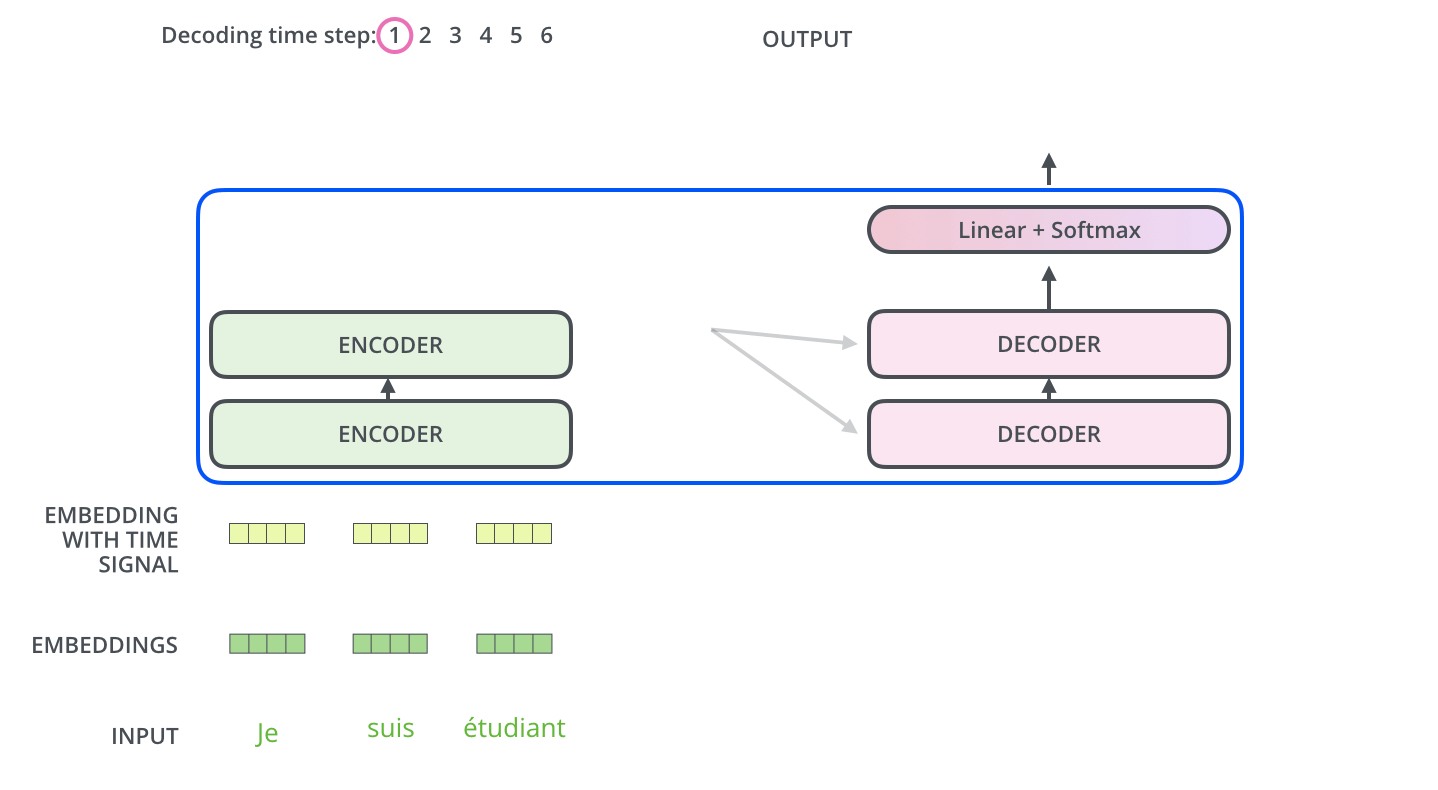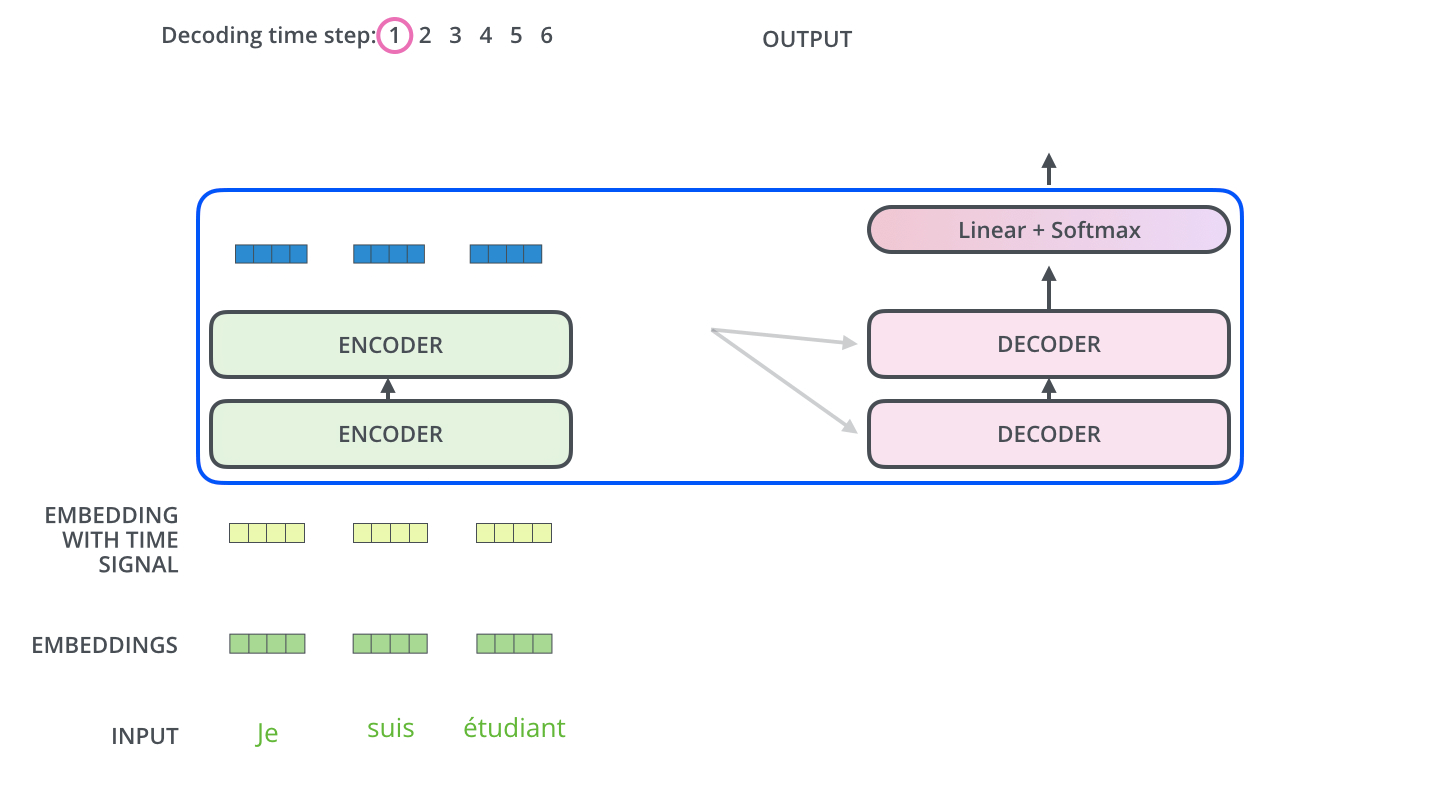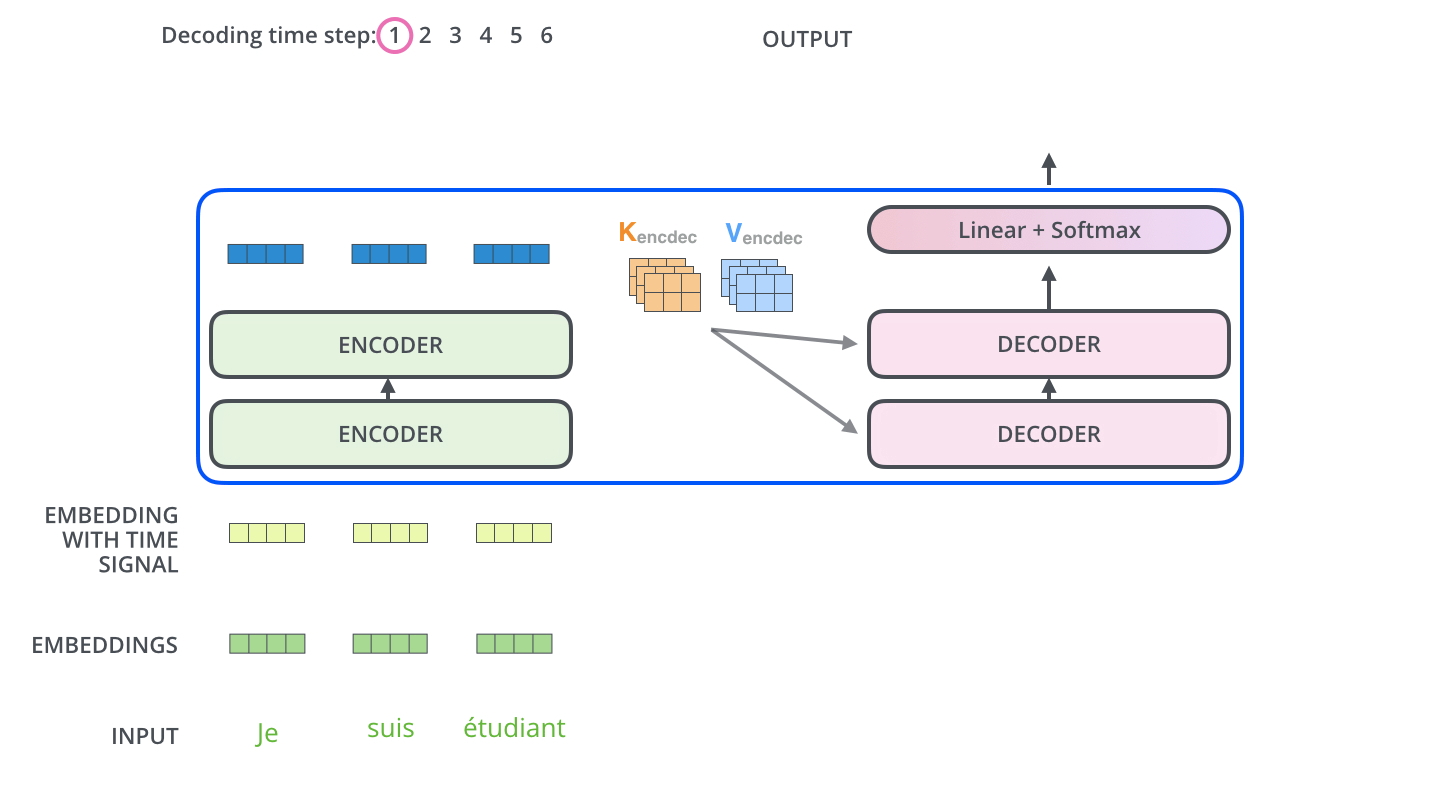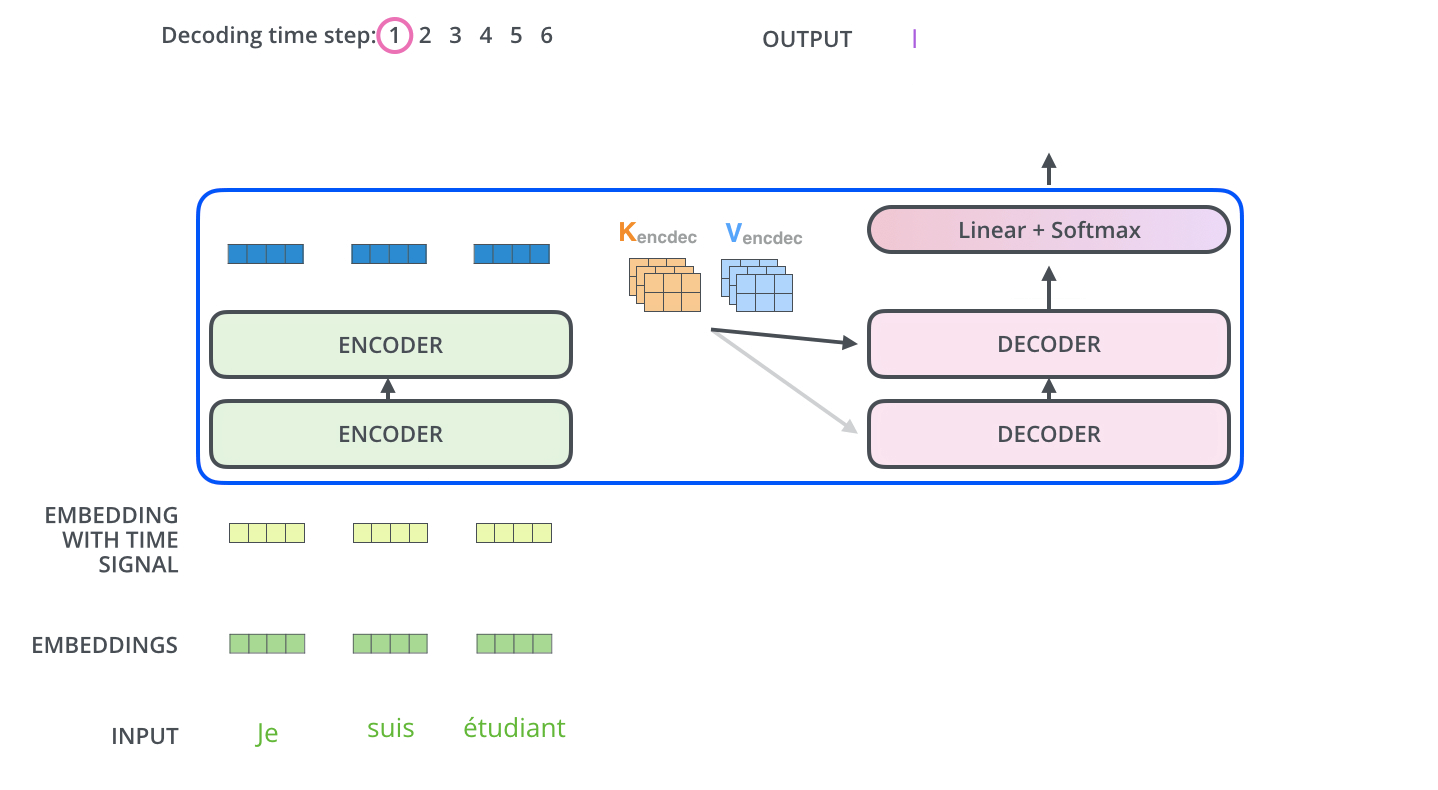
-The Decoder Side
encoder가 먼저 입력 시퀀스를 처리하기 시작함. 그다음 가장 윗단의 encoder의 출력은 attention 벡터들인 K와 V로 변형됨. Q. 마지막에서 두 번째 encoder layer에서 나온 z가 x로 들어가서 생성된 key, value 벡터를 가리키는 것인가? 이 벡터들은 이제 각 decoder의 “encoder-decoder attention” layer에서 decoder 가 입력 시퀀스에서 적절한 장소에 집중할 수 있도록 도와줌
- encoder의 입력에 했던 것과 동일하게 embed를 한 후 positional encoding을 추가하여 decoder에게 각 단어의 위치 정보를 더해줌.
-decoder 내에 있는 self-attention layer들은 encoder와는 조금 다르게 작동함.
Decoder에서의 self-attention layer는 output sequence 내에서 현재 위치의 이전 위치들에 대해서만 attend 할 수 있음. 이것은 self-attention 계산 과정에서 softmax를 취하기 전에 현재 스텝 이후의 위치들에 대해서 masking을 해줌으로써 가능해짐. Q. 내적 계산할 때 이전 위치의 벡터들에만 접근한다는 것인가?
“Encoder-Decoder Attention” layer 과 multi-head self-attention 의 유일한 차이점은 Query 행렬들을 그 밑의 layer에서 가져오고 Key 와 Value 행렬들을 encoder의 출력에서 가져온다는 점임
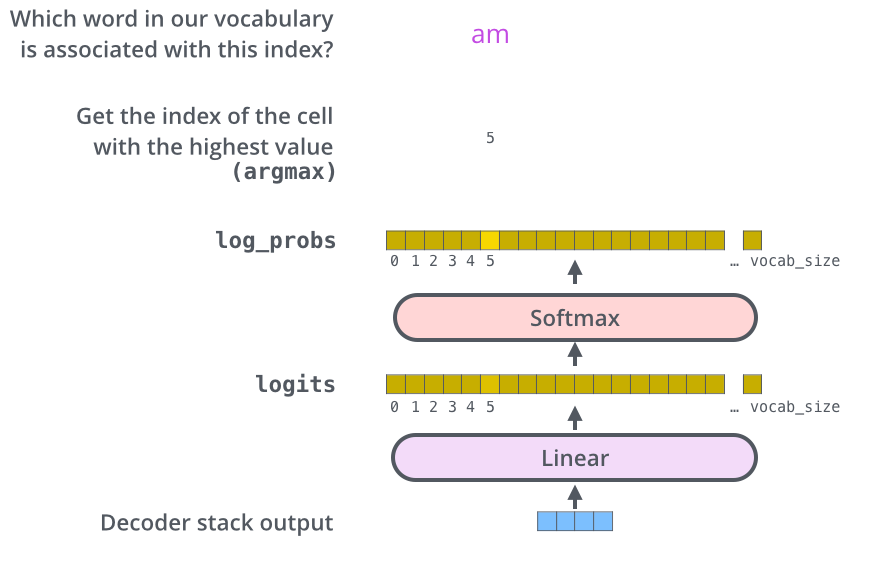
-The Final Linear and Softmax Layer
여러 개의 decoder를 거치고 난 후에는 소수로 이루어진 벡터 하나가 남게 됨. 마지막에 있는 Linear layer 과 Softmax layer가 이 하나의 벡터를 단어로 바꿈.
- Linear layer은 fully-connected 신경망으로 decoder가 마지막으로 출력한 벡터를 그보다 훨씬 더 큰 사이즈의 벡터인 logits 벡터로 투영시킴.
- 우리의 모델이 training 데이터에서 총 10,000개의 영어 단어를 학습하였다고 가정하자 (이를 우리는 모델의 “output vocabulary”라고 부른다). 그렇다면 이 경우에 logits vector의 크기는 10,000이 될 것임 – 벡터의 각 셀은 그에 대응하는 각 단어에 대한 점수가 됨. 이렇게 되면 Linear layer의 결과로서 나오는 출력에 대해서 해석을 할 수 있게 됨
- 그다음에 나오는 softmax layer는 이 점수들을 확률로 변환해주는 역할을 함. 가장 높은 확률 값을 가지는 셀에 해당하는 단어가 해당 스텝의 최종 결과물로서 출력됨.
-Loss Function
불어 merci를 thanks로 번역하는 예시

우리는 thanks라는 단어를 가리키는 확률 벡터 출력을 원함. 그러나 아직 학습이 되지 않은 상황에서는 각 word에 대해서 임의의 값을 출력함
확률 분포에 대해 바라는 것
1. 각 단어에 대한 확률 분포는 output vocabulary 크기를 가지는 벡터에 의해서 나타나짐
2. decoder가 첫 번째로 출력하는 확률 분포는 “i”라는 단어와 연관이 있는 cell에 가장 높은 확률을 줘야 함.
두 번째로 출력하는 확률 분포는 “am”라는 단어와 연관이 있는 cell에 가장 높은 확률을 줘야 함.
이와 동일하게 마지막 ‘<end of sentence>‘를 나타내는 다섯 번째 출력까지 이 과정은 반복됨 (‘<eos>’ 또한 그에 해당하는 cell을 벡터에서 가짐)
- 학습의 목표로 하는 벡터들과는 달리, 모델의 출력값은 비록 다른 단어들이 최종 출력이 될 가능성이 거의 없다 해도 모든 단어가 0보다는 조금씩 더 큰 확률을 가짐. 학습 과정을 도와주는 softmax layer의 매우 유용한 성질
- greedy decoding뿐만 아니라 다른 방법들도 존재함. 가장 확률이 높은 두 개의 단어를 저장하는 “beam search”가 있음
'부스트캠프 AI Tech' 카테고리의 다른 글
| Word Embedding: Word2Vec, GloVe (0) | 2022.10.11 |
|---|---|
| 22-10-11 깃헙특강 (0) | 2022.10.11 |
| Bag-of-Words, NaiveBayes Classifier (0) | 2022.10.11 |
| Custom Dataset 및 Custom DataLoader 생성 과제 정리 (0) | 2022.10.02 |
| Custom Model 제작 과제 정리 (0) | 2022.10.01 |


댓글